We received a PNG file that got somehow corrupted in transit. Reading the PNG
specification and
looking at the first couple of bytes in the header we saw that an 0x0d byte
was dropped. The file used 89 50 4e 47 0a 1a 0a as header instead of 89 50 4e
47 0d 0a 1a 0a. According to the PNG specification this is a feature to detect
if the file was converted from lf/cr to cr or cr to lf/cr. Now if that's not a
huge hint.
Ignoring the hint we badgered on and continued reading the PNG documentation and
playing around with the PNG after fixing the header. PNG files consist of
multiple chunks of different types. Each chunk consists of length (4b, big
endian), chunk type (4b), data (len), CRC-32 (4b). Writing a parser we saw that
the first couple of chunks were decoded just fine but then there was a bunch of
IDAT chunks (that contain a deflate-encoded stream of data) that did not match
up. The data was somewhat too short (shorter than the length description) and
the following IDATs did not line up. We tried both padding the data section with
additional 0x0 bytes and shortening the data sections but then the CRC-32 did no
longer match. After we fixed the CRC-32 we got a deflate decode error (in the
first IDAT chunk). Whenever decoding fails in a chunk, PNG readers give up as
they can no longer resynchronize.
Oh well, back to square one. Let's look again at that PNG linefeed conversion
thingy. After looking more closely we discovered that each chunk hat 0 to 3
bytes missing. Hm, this looks suspiciously like a Windows to Linux text format
conversion and might tell us that the file was converted in error. An earlier
internet search told us that it is impossible to undo this conversion (that's
why we tried the other options first) but if you try hard it might be possible
to recover.
So, firing up our Python skills we wrote a quick tool that parsers the PNG file,
fixes header and copies all correct chunks. For incorrect chunks we extract the
data and recursively try to find correct placements of 0x0d bytes. We walk
through the data section and for every 0x0a byte we find, we try to place an
0x0d byte before it until the length matches. We then test the CRC-32 and if
the CRC-32 now matches with the CRC-32 in the file we have successfully
recovered the data of this one chunk. This recovery option only works if there
are not too many 0x0d bytes that were removed from a specific chunk, otherwise
the search space would explode. Even with only a couple of chunks that had 3
bytes missing the search took roughly 15 minutes on a fast desktop (well, maybe
we should not have coded the search in Python).
Here's the recursive search function:
def find0a(buf, nra, crc, loc):
ptr = string.find(buf, "\x0a", loc)
while ptr != -1:
fbuf = buf[0:ptr]
fbuf = fbuf + "\x0d"
fbuf = fbuf + buf[ptr:]
if nra == 1:
tcrc = binascii.crc32(fbuf) & 0xffffffff
if tcrc == crc:
print "Found a match: "+str(hex(tcrc))
return fbuf
else:
tmp = find0a(fbuf, nra-1, crc, ptr+1)
if tmp != "":
return tmp
ptr = string.find(buf, "\x0a", ptr+1)
return ""
You can guess the remainder of the program (parsing the file format, then
parsing each chunk, looking at the length and searching for the next chunk by
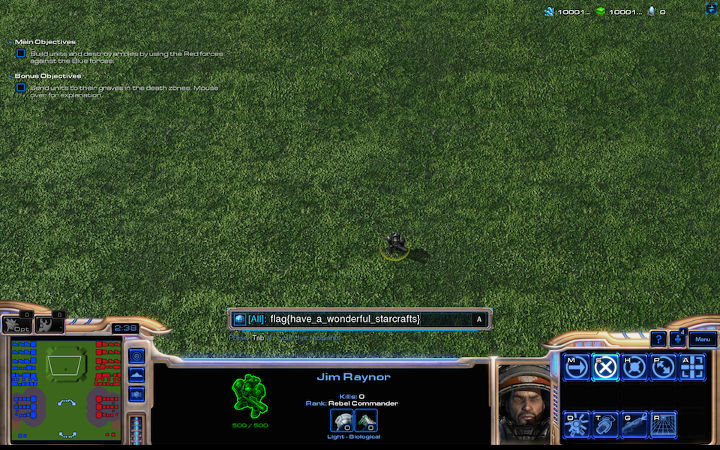
guessing how many bytes are missing. In the end we received a nice Startcraft
screenshot that told us the flag is flag{have_a_wonderful_starcrafts}. Hooray,
150 points!