Memory corruption (e.g., buffer overflows, random writes, memory allocation bugs, or uncontrolled format strings) is one of the oldest and most exploited problems in computer science. Low-level languages like C or C++ trade memory safety and type safety for performance: the compiler adds no bound checks and no type checks. The programmer itself is responsible for memory management and type casting which can lead to serious exploitable bugs. Prerequisites for a successful memory corruption are (i) that a pointer is pushed out of bounds (i.e., by iterating over the end of a buffer) or that a pointer becomes dangling (i.e., by freeing the object that a pointer points to) and (ii) that the attacker controls the value written to the out of bounds pointer, e.g., directly through an assignment or indirectly through some management function.
According to academia "buffer overflows are a solved problem" (quote paraphrased according to a member of the panel discussion about system security at INFOCOM'99 in New York). This answer is partially true as there are safe languages that provide memory safety and type safety like, e.g., Java or C#. These languages achieve memory safety by using automatic memory allocation and de-allocation (garbage collection) and adding bound checks to all buffers and structures. In addition, they add a strict type system that disallows casting between mutually exclusive types (e.g., from one struct to another completely disjoint struct).
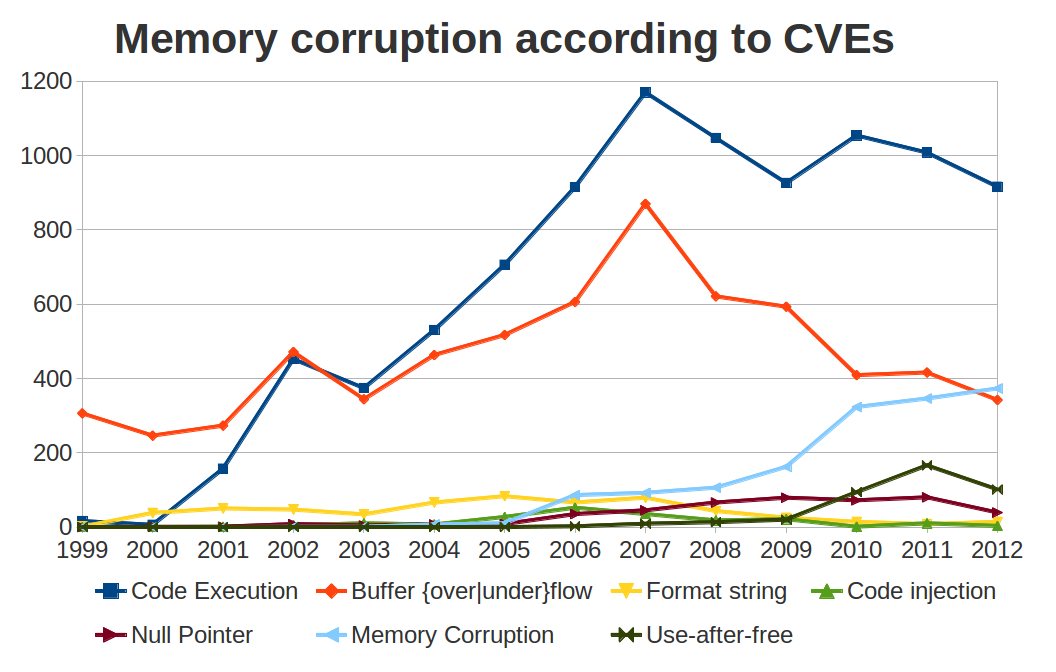
Figure 1: development of different classes of memory corruption attacks; based on CVE data.
On the other hand if we look at the development of memory corruption attacks since 1999 (Figure 1) we see that the number of these attacks rose until 2007 and is on an all-time high. So we can ask ourselves: what went wrong? On one hand there are new attack vectors (e.g., code-reuse attacks like Return Oriented Programming [39]) and safe languages have (i) too much overhead, (ii) too much latency (languages like Java do not support realtime execution because of stop-the-world garbage collection), (iii) missing support for legacy code, (iv) increased complexity, and (v) missing features like direct memory access for low-level applications.
The goal of this post is to explain different forms of memory corruption attacks and possible defenses that are deployed for current software systems. We will see that attack vectors and defense mechanisms are closely related and through this relation they evolve alongside. This article extends existing surveys and summaries [20, 36] by (i) a study that looks at the symbiosis between attacks and defenses and (ii) an analysis that explains why certain defense mechanisms are used in practice while other mechanisms never see wide adoption.
Attack model
An attacker with restricted privileges forces escalation, e.g., a remote user escalates to a local user account or a local user escalates to a privileged account. Our attack model assumes a white-box approach: the attacker knows both the source code and the binary of the application (so the attacker can execute binary analysis, evaluate the offsets of structs, and recover partial runtime information). A successful attack redirects the control flow to an alternate location and either injected code is executed or alternate data is used during the execution of existing code.
Evolution of attack vectors and defenses
Memory corruption attacks
A memory corruption attack relies on two properties: (i) a live pointer points to illegal data and (ii) said pointer is read or written by the application. An attacker can directly force the pointer out of bounds by exploiting a buffer overflow or underflow that writes across the bounds of a buffer or indirectly by messing with the object that the pointer points to: if this objects is freed or recycled then the pointer is dangling and points to illegal data.
In reality an attacker breaks these two steps into three steps:
- Preparation: first the pointer is redirected to an illegal memory location through a spatial bug (the pointer is forced out of bounds) or a temporal bug (making the pointer dangling). Possible attack vectors for the first step are buffer overflows/underflows on the stack or on the heap, integer overflows and underflows, format string exploits, double free, and other memory corruption.
- Setup: the attacker uses regular control flow of the application to dereference and write to the pointer. This second step exploits the spatial or temporal memory bug to disable code pointer integrity (all function pointer in the application point to correct and valid code locations), code integrity (the executable code of the application is unchanged),control-flow integrity (the control-flow of the application follows the original programmer-intended pattern), data-integrity (the data of the application is only changed by valid computation), or data-flow integrity (the data-flow in the application follows the intended pattern). A correct execution of an application relies on all of the before mentioned concepts to be enforced at all times. At this point the attacker has control over some data structures and possible targets are overwriting the return instruction pointer (RIP) on the stack, overwriting a function pointer (in the vtable, GOT, or in the .dtor section), forcing an exception (e.g., a NULL pointer dereference), or overwriting heap management data structures.
- Execution: finally the control flow is redirected to a location that is controlled by the attacker. The attacker uses either code corruption (new executable code is injected and/or existing code is changed and control-flow is redirected to the injected code), code-reuse attack (existing code is reused in an unintended way), a data-only attack (only the data of the application is changed to adapt the outcome of some computation), or information leakage (internal state is leaked to the attacker) to execute the malicious behavior.
Commonly used attack techniques
To execute malicious code an attacker usually uses one of three techniques: code injection, code reuse, or command injection. Each technique has its advantages and disadvantages and we will discuss them in detail.
Code injection is the oldest technique that achieves code execution. This technique attacks code integrity and injects executable code into data regions. Depending on flags in the page table any data on a memory page may be interpreted as machine code and executed. Prerequisites for this attack are (i) an executable memory area and a known address of a buffer to redirect control to, (ii) partial control of the contents of the buffer in the executable memory area, and (iii) a redirectable control flow to that partially controlled area of the buffer. This technique is nowadays no longer a problem due to increased hardware protection and non-executable memory pages (post 2006).
Code reuse is considered the response to the increased hardware protection against code injection. This technique circumvents control-flow integrity and/or code pointer integrity and reuses existing executable code with alternate data. So called gadgets (short sequences of instructions that usually pop/push registers and execute some computation followed by an indirect control flow transfer) are used to execute a set of prepared invocation frames. Prerequisites for this attack are (i) known addresses of necessary gadgets, (ii) a partially attacker-controlled buffer, and (iii) a redirectable control-flow transfer to the gadget that uses the first invocation frame. Protecting against this technique on a low level is very hard as control-flow integrity relies on checks and validity of all indirect control flow transfers.
Command injection is a third technique that prepares data that is passed to another application or to the kernel (e.g., SQL injection). The technique relies on the fact that unexepcted and unsanitized data is forwarded which leads to unexpected behavior. This technique attacks data integrity and/or data-flow integrity of the application. Prerequisite for this attack is only a missing or faulty sanity check. It is hard to protect against this attack because the source application needs to know about the kind of data the target expects and the context in which the target expects the data.
Defenses and their limitations
A multitude of different defenses have been proposed and discussed but only three defenses are actually used in practice: Data Execution Prevention (DEP), Address Space Layout Randomization (ASLR), and Canaries. None of the defenses is complete and each defense has particular weaknesses and limitations. In combination they offer complete protection against code injection attacks partial protection against code reuse attacks. In general, it can be said that the available defenses merely raise the bar against specific attacks but do not solve the problem of potential memory corruption.
Data Execution Prevention (DEP) prevents applications (and kernels) from code injection attacks. Newer processor add an additional flag (an eXecutable bit) to every entry in the page table. Each page has three bits: Readable (page is readable if set), Writable (page is writable if set), and eXecutable (page contains code that will be executed if control flow branches to this location). Before the eXecutable bit every page was automatically executable and there was no separation between code and data of an application. DEP is a technique that ensures that any page is either Writable xor eXecutable. This scheme protects against code injection attacks by ensuring that no new code can be injected after the application has started and all the code is loaded from disk. A drawback of DEP is that dynamic code generation for, e.g., just-in-time compilation, is not supported. DEP only protects against code injection attacks, all code reuse and other forms of attacks are still possible.
Address Space Layout Randomization (ASLR) is a probabilistic protection that randomizes the locations of individual memory segments (like code, heap, stack, data, memory mapped regions, or libraries). ASLR is an extension of both the operating system (as memory management system calls return random areas) and the loader that needs to load and resolve code at random locations. Hand written exploits often use absolute addressing and need to know the exact location of code they want to branch to or data they want to reuse. Due to random code and data location these attacks are no longer successful. Unfortunately this attack is prone to information leaks: if an attacker is able to extract the locations of specific buffers he/she can use this knowledge for an exploit if the program did not crash. ASLR basically turns a one-shot attack (pwnage on first try) into a two-shot attack (information leak first, pwnage second). A second drawback of ASLR is that some regions remain static upon every run (e.g., on Linux the main executable is often not compiled as position independent executable (PIE) and remains static for every run (including GOT tables, data regions, and code regions); so an attacker can use this static regions to just use a Return Oriented Programming (ROP) attack or more general a code reuse attack. An alternative to two-shot attacks is, e.g., heap spraying. Heap spraying uses the limited number of randomizable bits for a 32-bit memory image and fills the complete heap with copies of NOP slides and the exploit. When the exploit executes the chances are good that the exploit will hit one of the NOP slides and transfer control into the exploit (that is replicated millions of times on the heap).
Comparing PIE with non-PIE executables (Figure 2) [33] using the SPEC CPU2006 benchmarks shows that there is a performance difference of up to 25%. PIE executables reserve a register as a code pointer (due to the randomized locations indirect control flow transfer - indirect call or indirect jump - instructions need to a reference to know where to transfer control to). Due to the additional register usage register pressure increases which slows down overall execution. In reality few programs are compiled as PIE [43].
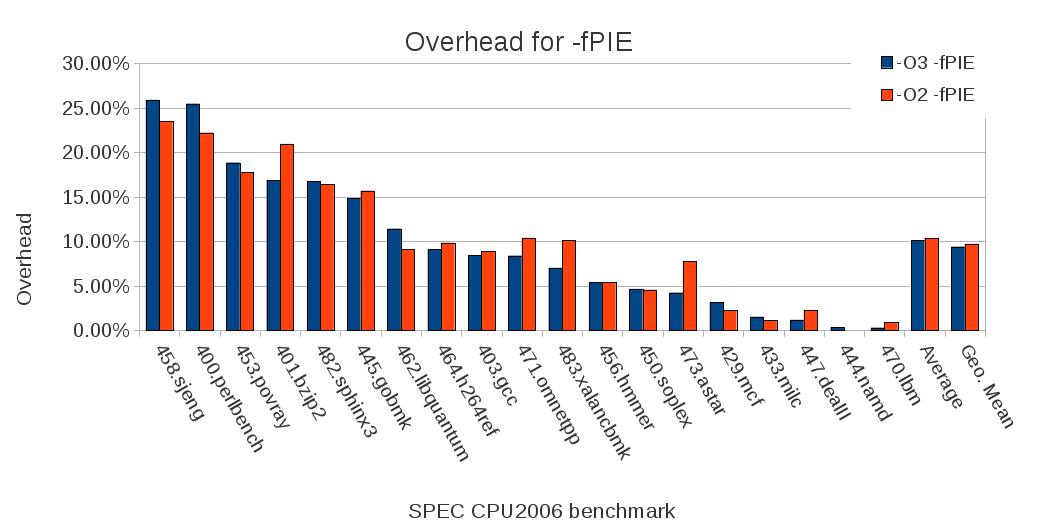
Figure 2: performance overhead for -fPIE on a 32-bit x86 system.
Canaries are a probabilistic protection against buffer overflows. The compiler places canary values (4 byte for x86 or 8 byte for x64) adjacent to buffers on the stack or on the heap. After every buffer modification the compiler adds an additional check to ensure that the canary is still intact, e.g., the compiler will add a check after a loop that copies values into a buffer. If the canary is replaced with some other value then the check code terminates the application. Canaries have several drawbacks: first, they only protect against continuous writes (i.e., buffer overflows) and not against any other form of direct overwrite. Second, they do not protect against data reads like information leaks. And third, they are, like ASLR, prone to information leaks. Only one random canary is generated for the execution of an application.
Limitations of defenses: DEP gives us code integrity and protects against code injection, but not against any other form of attacks. DEP relies on a hardware extension of the page table. Both canaries and ASLR are probabilistic and prone to information leaks. A one shot attack becomes a two shot attack. In addition, both canaries and ASLR are not free and there are some performance issues or data-layout issues.
The status of current protection is very limited. Current systems have complete protection against code integrity attacks through DEP which is in widespread use. There is limited protection for code pointer integrity and control-flow integrity through probabilistic protections like PointGuard [1], canaries and ASLR. So the code and control flow of an application is (at least partially) protected. What is missing is complete data protecion: there is no data integrity or data-flow integrity, although there are some proposals: WIT [4] using a points-to analysis for data integrity, and DFI using data encryption for data-flow integrity.
An interesting thing to note is that academia came up with many protection mechanisms but they were only used in practice when the burden of the exploits in the wild became too common and the attack techniques became widely known. Stack-based ASLR and canaries where introduced to protect against buffer overflows and code injection attacks on the stack but later extended to the heap and code regions to protect against code reuse attacks as well. DEP is used as an absolute protection against code injection attacks. This arms race between attackers and defenders is interesting to see and a well-equipped attacker has plenty of opportunities to exploit defense mechanisms on current systems. A second factor is that defense mechanisms always bring up a trade-off between available protection, legacy features that are no longer supported and possible performance impact. New defenses are therefore only introduced if the burden of the attacks is too high and too common.
Timeline
The following timeline shows how attacks and defenses developed alongside:
Attack Year Defense
Smashing the stack [5] 1996
ret-2-libc [18] 1997
1997 StackGuard [17]
Heap overflow techniques [14] 1999
Frame pointer overwrite [25] 1999
Bypassing StackGuard and 2000
StackShield [11]
Format string bugs [29] 2000
2000 libsafe and libverify protect library
functions [6]
2001 ASLR [30]
2001 ProPolice (stack canaries) are
introduced [23]
2001 FormatGuard [15]
Heap exploits and SEH frames [22] 2002
2002 Visual C++7 adds stack cookies
Integer overflows [19] 2002
2002 PaX adds W^X using segments and
Kernel ASLR [42]
2003 Visual Studio 2003: SAFESEH
2004 Windows XP2: DEP: RW heap and stack
ASLR only has 10bit randomness [37] 2004
Heap Spraying [38] 2004
2005 Visual Studio 2005: stack cookies
extended with shadow argument copies
2006 PaX protects kernel against NULL
dereferences
2006 Ubuntu 6.06 adds stack and heap ASLR
Advanced ret-2-libc [28, 36] 2007
Double free vulnerabilities 2007
2007 Ubuntu adds AppArmor [8]
2007 Windows Vista implements full ASLR
and heap hardening
ROP introduced [36] 2007
2008 Ubuntu 8.04 adds pointer obfuscation
for glibc and exec, brk, and
VDSO ASLR [41]
2008 Ubuntu 8.10 builds some apps with
PIE, fortify source, relro [41]
2009 Nozzle: heap spraying [35]
2009 Ubuntu 9.04 implements BIND NOW and
0-address protection [41]
2009 Ubuntu 9.10 implements NX [41]
Memory management vulnerabilities [9] 2010
New format string exploits [34] 2010
Failed defenses
Many defense mechanisms have been researched and proposed but none of them have seen widespread use except ASLR, DEP, and Canaries. The other defenses failed out of one of the following reasons: (i) too much overhead, (ii) missing programming features, or (iii) no support for legacy code . Too much overhead: as we see for ASLR (active for libraries, disabled for executables) the overhead that is tolerated must be less than 10% and must result in reasonable additional security guarantees. Other proposals that result in higher overhead or lower guarantees did not see widespread use next to the paper where they were published. ISA randomization [25, 7, 42] implements code integrity by randomizing the encoding of individual instructions but results in intolerable 2-3x overhead; PointGuard [1] protects function pointers using an encoding; data-flow integrity tracks the data of an application but results in 2-10x overhead; software-based fault isolation sandboxes [27, 2, 3, 34, 46] implement code and code pointer integrity by verifying all code before execution and result in 1.2x to 2x overhead. There are many other solutions in this category but we see that each solution solves one specific problem at too high a price.
Missing programming features: several proposed defense mechanisms implement a security guarantee by removing specific flexibility in code, data, or the original programming language. Many compiler-based security guarantees like control-flow integrity [1, 21] or data space randomization [4] rely on full program analysis where all code must be compiled and analyzed at the same time. This requirement removes the possibility for modularity (i.e., libraries) and requires that all code is loaded statically. Other features like code diversity or ILR make debugging of applications harder.
No support for legacy code: missing support for legacy code [28] is another problem for many failed defense mechanisms. Is is generally not feasible to rewrite all libraries or applications to add a new security guarantees. A large legacy code base in an existing language must still be supported with the new security features. It is OK to change limited aspects in the runtime system (e.g., ASLR, DEP) or during the compilation process (e.g., adding stack canaries in the data layout) but it is hard to add completely new features (e.g., annotations, rewriting the application in a new language).
Conclusion
Studying the existing defense mechanisms we see that three factors are key for adoption: (i) pressing need through (new) attack vectors, (ii) low overhead for the security solution, and (iii) compatibility to legacy code and legacy features. Only if there exists a clear migration path then the new defense mechanism will be adopted. The WarGames in memory will continue if the security community plays the reactive game. For defenses probabilistic mechanisms only raise the bar but they do not offer a solution. There is no reasonable defense mechanism that supports complete program integrity by combining (i) code integrity, (ii) low overhead control-flow integrity, and (iii) data-flow integrity. Until such a solution exists the war in memory continues and the existing exploit techniques will be used for fun and profit.
References
[1] Abadi, M., Budiu, M., Erlingsson, U., and Ligatti, J. Control-flow integrity. In CCS'05.
[2] Acharya, A., and Raje, M. MAPbox: using parameterized behavior classes to confine untrusted applications. In SSYM'00: Proc. 9th Conf. USENIX Security Symp. (2000), pp. 1--17.
[3] Aggarwal, A., and Jalote, P. Monitoring the security health of software systems. In ISSRE'06: 17th Int'l Symp. Software Reliability Engineering (nov. 2006), pp. 146 --158.
[4] Akritidis, P., Cadar, C., Raiciu, C., Costa, M., and Castro, M. Preventing memory error exploits with WIT. In SP'08: Proc. 2008 IEEE Symposium on Security and Privacy (2008), pp. 263--277.
[5] Aleph1. Smashing the stack for fun and profit. Phrack 7, 49 (Nov. 1996).
[6] Baratloo, A., Singh, N., and Tsai, T. Transparent run-time defense against stack smashing attacks. In Proc. Usenix ATC (2000), pp. 251--262.
[7] Barrantes, E. G., Ackley, D. H., Forrest, S., and Stefanovi, D. Randomized instruction set emulation. ACM Transactions on Information System Security 8 (2005), 3--40.
[8] Bauer, M. Paranoid penguin: an introduction to Novell AppArmor. Linux J. 2006, 148 (2006), 13.
[9] blackngel.The house of lore: Reloaded. Phrack 14, 67 (Nov. 2010).
[10] Bletsch, T., Jiang, X., Freeh, V. W., and Liang, Z. Jump-oriented programming: a new class of code-reuse attack. In ASIACCS'11: Proc. 6th ACM Symp. on Information, Computer and Communications Security (2011), pp. 30--40.
[11] Bulba, and Kil3r. Bypassing stackguard and stackshield. Phrack 10, 56 (Nov. 2000).
[12] Checkoway, S., Davi, L., Dmitrienko, A., Sadeghi, A.-R., Shacham, H., and Winandy, M. Return-oriented programming without returns. In CCS'10: Proceedings of CCS 2010 (2010), A. Keromytis and V. Shmatikov, Eds., ACM Press, pp. 559--572.
[13] Chen, P., Xing, X., Mao, B., Xie, L., Shen, X., and Yin, X. Automatic construction of jump-oriented programming shellcode (on the x86). In ASIACCS'11: Proc. 6th ACM Symp. on Information, Computer and Communications Security (2011), ACM, pp. 20--29.
[14] Conover, M.w00w00 on heap overflows.
[15] Cowan, C., Barringer, M., Beattie, S., Kroah-Hartman, G., Frantzen, M., and Lokier, J. Formatguard: automatic protection from printf format string vulnerabilities. In SSYM'01: Proc. 10th USENIX Security Symp. (2001).
[16] Cowan, C., Beattie, S., Johansen, J., and Wagle, P. PointguardTM: protecting pointers from buffer overflow vulnerabilities. In SSYM'03: Proc. 12th USENIX Security Symp. (2003).
[17] Cowan, C., Pu, C., Maier, D., Hintony, H., Walpole, J., Bakke, P., Beattie, S., Grier, A., Wagle, P., and Zhang, Q. StackGuard: automatic adaptive detection and prevention of buffer-overflow attacks. In SSYM'98: Proc. 7th USENIX Security Symp. (1998).
[18] Designer, S. Return intolibc.
[19] Dowd, M., Spencer, C., Metha, N., Herath, N., and Flake, H. Professional source code auditing, 2002.
[20] Erlingsson, U. Low-level software security: Attacks and defenses. FOSAD'07: Foundations of security analysis and design (2007), 92--134.
[21] Erlingsson, U., Abadi, M., Vrable, M., Budiu, M., and Necula, G. C. XFI: Software guards for system address spaces. In OSDI'06.
[22] Flake, H. Third generation exploitation, 2002.
[23] Haas, P. Advanced format string attacks, DEFCON 18 2010.
[24] Hiroaki, E., and Kunikazu, Y. ProPolice: Improved stack-smashing attack detection. IPSJ SIG Notes (2001), 181--188.
[25] Kc, G. S., Keromytis, A. D., and Prevelakis, V. Countering code-injection attacks with instruction-set randomization. In CCS'03: Proc. 10th Conf. on Computer and Communications Security (2003), pp. 272--280.
[26] klog. The frame pointer overwrite. Phrack 9, 55 (Nov. 1999).
[27] McCamant, S., and Morrisett, G. Evaluating SFI for a CISC architecture. In SSYM'06.
[28] Necula, G., Condit, J., Harren, M., McPeak, S., and Weimer, W. CCured: Type-safe retrofitting of legacy software. vol. 27, ACM, pp. 477--526.
[29] Nergal. The advanced return-into-lib(c) exploits. Phrack 11, 58 (Nov. 2007).
[30] Newsham, T. Format string attacks, 2000.
[31] OWASP. Definition of format string attacks.
[32] PaX-Team. PaX ASLR (Address Space Layout Randomization), 2003.
[33] Payer, M. Too much pie is bad for performance. 2012.
[34] Payer, M., and Gross, T. R. Fine-grained user-space security throughvirtualization. In VEE'11.
[35] Payer, M., and Gross, T. R. String oriented programming: When ASLR is notenough. In Proc. 2nd Program Protection and Reverse Engineering Workshop (2013).
[36] Pincus, J., and Baker, B. Beyond stack smashing: Recent advances in exploiting buffer overruns. IEEE Security and Privacy 2 (2004), 20--27.
[37] Planet, C. A eulogy for format strings. Phrack 14, 67 (2010).
[38] Ratanaworabhan, P., Livshits, B., and Zorn, B. Nozzle: A defense against heap-spraying code injection attacks. In Proceedings of the Usenix Security Symposium (Aug. 2009).
[39] Shacham, H. The geometry of innocent flesh on the bone: Return-into-libc without function calls (on the x86). In CCS'07: Proc. 14th Conf. on Computer and Communications Security (2007), pp. 552--561.
[40] Shacham, H., Page, M., Pfaff, B., Goh, E.-J., Modadugu, N., and Boneh, D. On the effectiveness of address-space randomization. In CCS'04: Proc. 11th Conf. Computer and Communications Security (2004), pp. 298--307.
[41] SkyLined. Internet explorer iframe src&name parameter bof remotecompromise, 2004.
[42] Sovarel, A. N., Evans, D., and Paul, N. Where's the FEEB? the effectiveness of instruction set randomization. In SSYM'05: Proc. 14th Conf. on USENIX Security Symposium (2005).
[43] List of Ubuntu programs built with PIE. March 2013.
[44] Ubuntu securityfeatures, May 2012.
[45] van de Ven, A., and Molnar, I. Exec shield. 2004.
[46] Wahbe, R., Lucco, S., Anderson, T. E., and Graham, S. L. Efficient software-based fault isolation. In SOSP'93.