Side channel attacks such as Spectre or Meltdown allow data leakage from an unwilling process. Until now, transient execution side channel attacks primarily leveraged cache-based side channels to leak information. The very purpose of a cache, that of providing faster access to a subset of data, enables information leakage. While the world focused on a string of exploits leveraging caches (and the memory hierarchy pyramid) and defenders tried to block data leakage through it, we look at the core tenet enabling the channel: contention.
Contention in a CPU is not limited to cache capacity; it manifests itself in a variety of forms when resources are shared. Freely sharing resources among untrusted entities allows an attacker process to infer when another (victim) process is contending for the resource, thereby slowing down the attacker.
A less obvious form of contention arises in Simultaneously Multi-Threaded (SMT) cores. The latter lay the foundation for nearly all modern x86 CPUs, IBM POWER8, Oracle T5 and Cavium ThunderX2/X3. In SMT, scheduling units called ports are shared among threads of execution which can be exploited to leak information. Port contention as a phenomenon has been previously discussed by Anders Fogh in his 2016 blog post.
We precisely characterize the port-induced side channel (that we call SMoTher) and demonstrate that it is possible to detect a sequence as small as a single (schedulable) instruction tied at design time to a specific subset of ports by leveraging contention. Leveraging SMoTher (instead of a cache-based side channel), we present a powerful, practical transient execution attack to leak secrets that may be held in registers or the closely-coupled L1 cache, called SMoTherSpectre. The full paper is on arXiv, the work is a collaboration between the EPFL HexHive and PARSA labs, and IBM Research Zurich and joint work between Atri Bhattacharyya, Alexandra Sandulescu, Matthias Neugschwandtner, Alessandro Sorniotti, Babak Falsafi, Mathias Payer, and Anil Kurmus.
Simultaneous multi-threading and scheduling
A Simultaneously Multi-threaded (SMT) CPU fetches and executes instructions for more than one thread on the same core. To the operating system/user, it appears as a greater number of logical cores than physical cores. The former is used to denote the capability to execute a thread, while the latter is the physical implementation of a unit (execution pipeline, registers, caches) called a core. These (colocated) threads have a few dedicated components per thread (fetch unit and architectural registers), while sharing the rest of the pipeline (branch predictors, reservation station, ports, execution units). Implementations differ in which components are shared or dedicated and the number of threads per physical core.
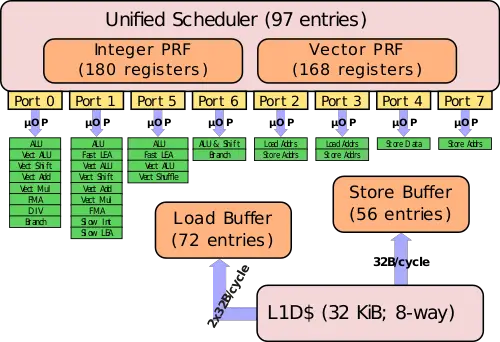
A typical modern, out-of-order processor schedules micro-ops from an unified reservation station to specialized execution units. See this presentation for an overview of scheduling on recent Intel microarchitectures. Core-series processors contain 5-8 ports to perform this scheduling. Each port is responsible for a fixed subset of execution units. Intel Skylake processors, specifically, contain eight ports. Four of them (0,1,5 and 6) are used to schedule operations to integer, floating-point, vector execution units among others. The other four ports handle loads, stores, and address generation operations. The execution units for the most commonly executed micro-ops are replicated and associated with multiple ports. With SMT, micro-ops from both co-located threads may reside in the same reservation station(s). In each cycle, a single micro-op from either thread may be scheduled by each port. See scheduling Ports on Intel Skylake processors for details of Intel Skylake scheduling.
{kind=link}
SMoTher
When SMT threads have ready micro-ops which can use the same port, they must
contend for it each cycle. Each thread would need to wait for a few cycles when
the port under contention chooses to schedule a micro-op from another thread,
causing a slowdown. This slowdown is detectable (by taking timestamps using
rdtsc on Intel's CPUs), and allows a specially crafted thread to measure the
co-located thread's utilization of a port.
Suppose threads A (Attacker) and V (Victim) run on the same physical Skylake
core, where crc32 is scheduled by port 1 and fadd is scheduled by port 5. If
a thread V only uses other ports (example, running fadds), thread A running 20
one-cycle crc32 instructions should require 20 cycles. However, if the
reservation station also contains a single ready crc32 instruction from
thread V, there should be one cycle where port 1 chooses it over the micro-ops
from A. Overall, thread A now runs the same instruction in 21 cycles, which is a
5% slowdown. Longer sequences with contention have lead to attacker slowdown
up to 35% in our experiments.
Each instruction in a sequence of code can be scheduled on specific ports. This allows us to create a port-fingerprint for every sequence, consisting of the expected utilization of each of the ports while scheduling that sequence. For a pair of victim sequences, V_a and V_b, with different port-fingerprints, a carefully crafted attacker thread can identify which victim sequence is concurrently run. Essentially, the attacker chooses one or more ports for which the victim sequences differ in the signature. By timing instructions specifically scheduled on these ports, the attacker can measure contention. Higher contention means that a concurrent victim is using the same ports (and vice versa), identifying the sequence. We call such pairs of instruction sequences SMoTher-differentiable.
To leak information, we look at data-dependent control flow (conditional
branches) leading to SMoTher-differentiable sequences (as branch target and
fallthrough). We call this a SMoTher-gadget. The attacker can identify the
sequence following the branch, and thereby infer the outcome of the condition.
The information leaked depends on the branch condition. Common examples include
specific bits in registers or memory (for example, TEST 0x1, al; jz TGT, or
CMPB 0x0, (rdx); jl TGT).
SMoTherSpectre
SMoTherSpectre is a speculative code-reuse attack. Speculative execution at particular points of a victim's execution is influenced to execute SMoTher-gadgets, leaking information.
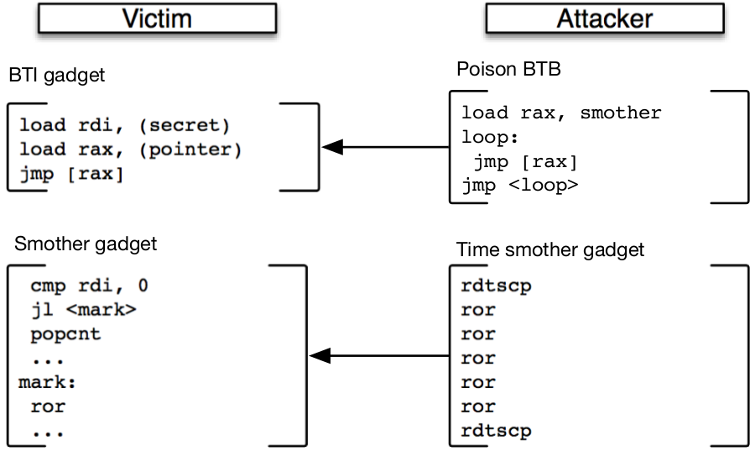
As an example, an attacker can use branch target injection (BTI) to redirect the
speculative execution following an indirect jump/call (until the target is
calculated) on a co-located victim process (shared branch predictor). This code
sequence, including the indirect branch, is named the BTI gadget. At this
point, we require a register or a memory location (with a pointer to it) to hold
the secret to be leaked. The code below is an example BTI gadget, where a secret
is loaded into rdi and the indirect jump will eventually branch to the
pointer target loaded into rax.
BTI gadget:
load rdi, (secret)
load rax, (pointer)
jmp [rax]
The poisoned target leads the victim to execute a different data-dependent
control-flow sequence--i.e., a conditional branch--somewhere in the victim code.
The condition must use the secret, so that the branch leaks the outcome of the
condition if the attacker can figure out which instructions the victim executed
just afterwards (i.e., either the branch target or the fall-through). For
SMoTher-gadgets, conditional branches where the two subsequent paths are
SMoTher-differentiable, the attacker can figure out if the branch was taken or
not taken by introducing contention on one or more ports which the target and
fallthrough use for different number of cycles. In the SMoTher-gadget shown
below, crc32 is scheduled by port 1 on Skylake, while ror is scheduled on
ports 0 and 6.
SMoTher gadget:
cmp rdi, 0
jl <mark>
crc32
crc32
...
mark:
ror
ror
...
An attacker running a sequence of crc32 instructions will contend on port 1
if the victim branch falls though and runs crc32 instructions too. The
slowdown due to contention can be detected by the attacker, using rdtsc
timestamps to count the number of cycles taken to run its sequence, and allows
it to infer that the victim's secret is not less than 0.
Gadgets
SMoTherSpectre requires two gadgets in the victim code base:
- A BTI gadget (to trigger speculation):
C/C++ compilers typically use indirect call instructions to implement calls
using function pointers/virtual-function calls in code which does not deploy
repoline defences. OpenSSL's EVP library uses such a pointer to, e.g.,
encrypt/decrypt using the selected cipher.
i = ctx->cipher->do_cipher(ctx, out, in, inl);
Further, a secret argument may be held in registers. In the example above, registerrdxholds a pointer to the secret plaintext being encrypted. - A SMoTher gadget (to leak the secret):
Every conditional branch in a victim's binary is a potential SMoTher gadget.
In fact, even unintended sequences which may be interpreted as a conditional
jump can be used (similar to ROP). However, an attacker needs to be able to
differentiate between the target and fallthrough sequences using port contention.
It turns out that hundreds to thousands of such sequences exist in
glibc(with different degrees of SMoTher-differentiability). The paper describes in more detail our methodology for finding and ranking SMoTher-gadgets.
The vast availability of SMoTher gadgets makes SMoTherSpectre such a powerful attack. While the first stage is similar to other speculative execution attacks, the side channel to leak information is different and more readily available than cache-based side channels. While each step leaks only one bit of information (the conditional branch that depends on the secret value was taken or not taken), SMoTher-gadgets are more readily available and can be combined the leak information.
Evaluation
We release the proof of concept code to enable other researchers to reproduce, evaluate, and assess this side channel. It uses the gadgets described above. Separate processes are used for the attacker and victim. Per iteration of the experiment, a randomly-generated bit (representing the victim's secret) is written by the victim process to a file, while the attacker writes its guess to another file. For each secret, we repeat the attack multiple times to allow the attacker to get multiple samples. Multiple samples allows the attacker to eliminate some of the noise that invariably creeps into a timing experiment at such fine granularity. We run 1,000 iterations and compare the files in post-processing to calculate the attacker's accuracy in guessing the secret.
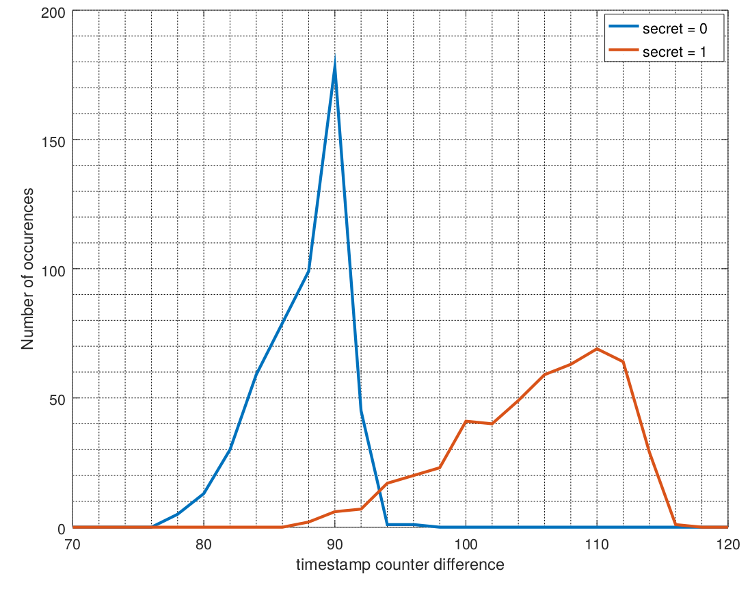
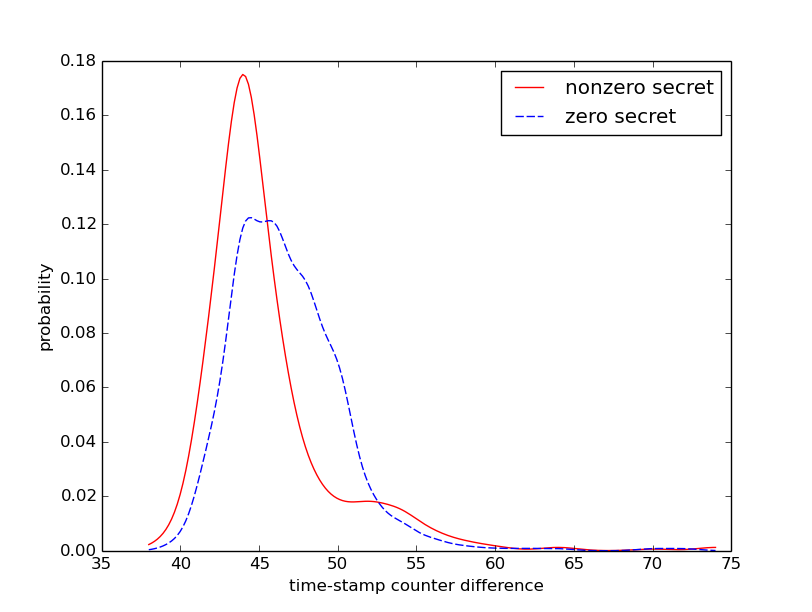
The histogram of the attacker's timing for the crc32 sequence in the SMoTher
phase shows separate plots for when the actual secret is zero or one.
Specifically, the attacker's timing is the average over 9 runs with the same
secret. This figure clearly shows that an attacker can use a threshold of 94
cycles to make a guess of the secret with high confidence.
Overall, our attacker was able to guess the secret with an accuracy from 60% (with one sample) to 98% (with 9 samples).
OpenSSL exploit
We also created a concept exploit for OpenSSL's (commit f1d49ed, dated
27-Nov-2018) high level EnVeloP (EVP) API. We modelled a victim program using
OpenSSL to encrypt data. Specifically, the program calls EVP_EncryptUpdate to
encrypt chunks of data. An indirect call in the function serves as our BTI
gadget.
At the BTI gadget, the register rdx holds a pointer to the plaintext being
encrypted (victim secret). A SMoTher-gadget from glibc is used, comparing the
first byte in memory referenced by rdx against zero. In effect, this is
leaking information about the first byte of the plaintext.
The distribution of the attacker's timing with different secret values are distinguishable by statistical tests such as Student's t-test, implying that an attacker which is able to run multiple encryption runs of the same plaintext can identify the secret.
Mitigation
Mitigating SMoTherSpectre is possible by mitigating the port contention side channel or the transient execution side channel (BTI in our PoC).
There are a range of mitigations for BTI (commonly known as Spectre v2 mitigations), including enabling the Single Thread Indirect Branch Predictors (STIBP) feature on Intel processors. We saw that microcode updates (https://downloadcenter.intel.com/search?keyword=linux+microcode) dated 2017-07-07 and after as published by Intel prevented BTI on our released PoC code. All security-critical userspace programs should be compiled with retpolines.
However, BTI is one of multiple avenues for influencing indirect branches (or returns) on victim processes. Newer Spectre variants continue to propose alternate methods for influencing branch speculation. Therefore, defense against SMoTher is required to fully mitigate this transient execution attack.
The general idea of preventing SMoTher leaking information is to ensure that two
threads with different privileges (in the general sense) do not compete for the
same execution port. An obvious scenario is threads from separate users sharing
a physical core. However, in certain cases, threads from the same Linux user
can represent different mutually-untrusting entities. Therefore, the strongest
defence is disabling simultaneous multi-threading.
Disclosure
We discovered the SMoTher side channel in June 2018 and developed the SMoTherSpectre speculative side channel proof of concept in November 2018. The co-authors at IBM Research disclosed the findings internally to IBM. We disclosed the vulnerability to Intel (on December 05, 2018) and to OpenSSL (on December 05, 2018). AMD was also notified as part of IBM's internal disclosure process. After the acknowledgement of receiving our PoC, we did not receive any feedback from Intel or OpenSSL. The IBM internal disclosure process completed on February 28, 2019 and we are releasing the details of the vulnerability on March 06, 2019.
The full paper is on arXiv. The PoC code enables reproduction. Contact: Mathias Payer or @gannimo on Twitter.