Software contains bugs and some bugs are exploitable. Mitigations protect our systems in the presence of these vulnerabilities, often stopping the program when detecting a security violation. The alternative is to discover bugs during development and fixing them in the code. Despite massive efforts, finding and reproducing bugs is incredibly hard. Fuzzing is an efficient way of discovering security critical bugs by triggering exceptions such as crashes, memory corruption, or assertion failures automatically (or with a little help) and comes with a witness (proof of the vulnerability) that allows developers to reproduce the bug and fix it.
Software testing broadly focuses on discovering and patching bugs during development. Unfortunately, a program is only secure if it is free of unwanted exceptions and therefore requires proving the absence of security violations. For example, a bug becomes a vulnerability if any attacker-controlled input reaches a program location that allows a security violation such as memory corruption. Software security testing therefore requires reasoning about all possible executions of code at once to produce a witness that violates the security property. As Edsger W. Dijkstra said in 1970: "Program testing can be used to show the presence of bugs, but never to show their absence!"
System software such as browsers, runtime systems, or kernels are written in low level languages (such as C and C++) that are prone to exploitable, low level defects. Undefined behavior is at the root of low level vulnerabilities, e.g., invalid pointer dereferences resulting in memory corruption, casting to an incompatible type leading to type confusion, integer overflows, or API confusion. To cope with the complexity of current programs, companies like Google, Microsoft, or Apple integrate dynamic software testing into their software development cycle to find bugs.
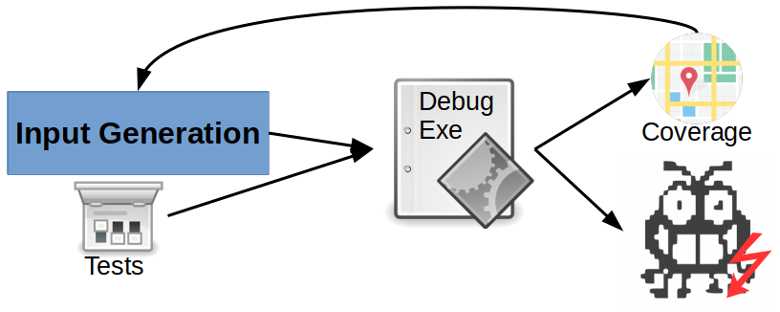
Figure 1: Fuzzing consists of an execution engine and an input generation process to run executables (which are often instrumented with explicit memory safety checks). The input generation mechanism may leverage existing test cases and execution coverage to generate new test inputs. For each discovered crash, the fuzzer provides a witness (input that triggers the crash).
Fuzzing, the process of providing random input to a program to trigger unintended crashes, has been around since the early 80ies. Recently, we are seeing a revival of fuzzing techniques with several papers improving effectiveness at each top tier security conference. The idea of fuzzing is incredibly simple: execute a program in a test environment with random input and detect if it crashes. The fuzzing process is inherently sound but incomplete. By producing test cases and observing if the program under test crashes, fuzzing produces a witness for each discovered crash. As a dynamic testing technique, fuzzing is incomplete as it will neither cover all possible program paths nor data-flow paths except when run for an infinite amount of time, for non-trivial programs. Fuzzing strategies are inherently an optimization problem where the available resources are used to discover as many bugs as possible, covering as much of the program functionality as possible through a probabilistic exploration process. Due to its nature as a dynamic testing technique, fuzzing faces several unique challenges:
- Input generation: fuzzers generate inputs based on a mutation strategy to explore new state. Being aware of the program structure allows the fuzzer to tailor input generation to the program. The underlying strategy determines how effectively the fuzzer explores a given state space. A challenge for input generation is the balance between exploring new paths (control flow) and executing the same paths with different input (data flow).
- Execution engine: the execution engine takes newly generated input and executes the program under test with that input to detect flaws. Fuzzers must distinguish between benign and buggy executions. Not every bug results in an immediate segmentation fault and detecting state violation is a challenging task, especially as code generally does not come with a formal model. Additionally, the fuzzer must disambiguate crashes to uniquely identify bugs without missing true positives.
- Coverage wall: fuzzing struggles with some aspects of code such as fuzzing a complex API, checksums in file formats, or hard comparisons such as a password check. Preparing the fuzzing environment is a crucial step to increase the efficiency of fuzzing.
- Evaluating fuzzing effectiveness: defining metrics to evaluate the effectiveness for a fuzzing campaign is challenging. For most programs the state space is (close to) infinite and fuzzing is a brute force search in this state space. Deciding when to, e.g., move to another target, path, or input is a crucial aspect of fuzzing. Orthogonally, comparing different fuzzing techniques requires understanding of the strengths of a fuzzer and the underlying statistics to enable fair comparison.
Input generation
Input generation is essential to the fuzzing process as every fuzzer must automatically generate test cases to be run on the execution engine. The cost for generating a single input must be low, following the underlying philosophy of fuzzing where iterations are cheap. Through input generation, the fuzzer implicitly selects which parts of the program under test are executed. Input generation must balance data-flow and control-flow exploration (discovering new code areas compared to revisiting previously executed code areas with alternate data) while considering what areas to focus on. There are two fundamental forms of input generation: model-based input generation and mutation-based input generation. The first is aware of the input format while the latter is not.
Knowledge of the input structure given through a grammar enables model-based input generation to produce (mostly) valid test cases. The grammar specifies the input format and implicitly the explorable state space. Based on the grammar, the fuzzer can produce valid test cases that satisfy many checks in the program such as valid state checks, dependencies between fields, or checksums such as a CRC32. For example, without an input model the majority of randomly generated test cases will fail the equality check for a correct checksum and quickly error out without triggering any complex behavior. The model allows input generation to balance the generated test inputs according to the underlying input protocol. The disadvantage of model-based input generation is the need for an actual model. Most input formats are not formally described and will require an analyst to define the intricate dependencies.
Mutation-based input generation requires a set of seed inputs that trigger valid functionality in the program and then leverages random mutation to modify these seeds. Providing a set of valid inputs is significantly easier than formally specifying an input format. The input mutation process then constantly modifies these input seeds to trigger interesting behavior.
Regardless of the input mutation strategy, fuzzers need a fitness function to assess the quality of the new input, and guide the generation of new input. A fuzzer may leverage the program structure and code coverage as fitness functions. There are three different approaches to observing the program during fuzzing to provide input to the fitness function. Whitebox fuzzing infers the program specification through program analysis, but often results in untenable cost For example, the SAGE whitebox fuzzer leverages symbolic execution to explore different program paths. Blackbox fuzzing blindly generates new input without reflection. The lack of a fitness function limits blackbox fuzzing to functionality close to the provided test cases. Greybox fuzzing leverages light-weight program instrumentation instead of heavier-weight program analysis to infer coverage during the fuzzing campaign itself, merging analysis and testing.
Coverage-guided greybox fuzzing combines mutation-based input generation with program instrumentation to detect whenever a mutated input reaches new coverage. Program instrumentation tracks which areas of the code are executed and the coverage profile is tied to specific inputs. Whenever an input mutation generates new coverage, it is added to the set of inputs for mutation. This approach is incredibly efficient due to the low cost instrumentation but still results in broad program coverage. Coverage-guided fuzzing is the current de-facto standard, with AFL [Zal13l] and honggfuzz [Swi10] as the most prominent implementations. These fuzzers leverage execution feedback to tailor input generation without requiring deep insight into the program structure by the analyst.
A difficulty for input generation is the optimization between discovering new paths and evaluating existing paths with different data. While the first increases coverage and explores new program areas, the latter explores already covered code through different data-flow. Existing metrics have a heavy control-flow focus as coverage measures how much of the program has already been explored. Data-flow coverage is only measured implicitly with inputs that execute the same paths but with different data values. A good input generation mechanism balances the explicit goal of extending coverage with the implicit goal of rerunning the same input paths with different data.
Execution engine
After the fuzzer generates test cases, it must execute them in a controlled environment and detect when a bug is triggered. The execution engine takes the fuzz input, executes the program under test, extracts runtime information such as coverage, and detects crashes. Ideally a program would terminate whenever a flaw is triggered. For example, an illegal pointer dereference on an unmapped memory page results in a segmentation fault which terminates the program, allowing the executing engine to detect the flaw. Unfortunately, only a small subset of security violations will result in program crashes. Buffer overflows into adjacent memory locations, for example, may only be detected later if the overwritten data is used or may never be detected at all. The challenge for this component of the fuzzing process is to efficiently enable the detection of security violations. For example, without instrumentation, only illegal pointer dereferences to unmapped memory, control-flow transfers to non-executable memory, division by zero, or similar exceptions will trigger an exception.
To detect security violations early, the program under test may be instrumented with additional software guards. Security violations through undefined behavior for code written in systems languages are particularly tricky. Sanitization analyzes and instruments the program during the compilation process to detect security violations. Address Sanitizer (ASan) [SBP+12], the most commonly used sanitizer, probabilistically detects spatial and temporal memory safety violations by placing red-zones around allocated memory objects, keeping track of allocated memory, and carefully checking memory accesses. Other LLVM-based sanitizers cover undefined behavior (UBSan), uninitialized memory (MSan), or type safety violations through illegal casts [JBC+17]. Each sanitizer requires certain instrumentation that increases the performance cost. The usability of sanitizers for fuzzing therefore has to be carefully evaluated as, on one hand, it makes error detection more likely but, on the other hand, reduces fuzzing throughput.
The main goal of the execution engine is to execute as many inputs per second as possible. Several fuzzing optimizations such as fork servers, persistent fuzzing, or special OS primitives reduce the time for each execution by adjusting system parameters. Fuzzing with a fork server executes the program up to a certain point and then forks new processes at that location for each new input. This allows the execution engine to skip over initialization code that would be the same for each execution. Persistent fuzzing allows the execution engine to reuse processes in a pool with new fuzzing input, resetting state between executions. Different OS primitives for fuzzing reduce the cost of process creation by, e.g., simplifying page table creation and optimizing scheduling for short lived processes.
Modern fuzzing is heavily optimized and focuses on efficiency, measured by the number of bugs found per time. Sometimes, fuzzing efficiency is measured implicitly by the number of crashes found per time, but crashes are not unique and many crashes could point to the same bug. Disambiguating crashes to locate unique bugs is an important but challenging task. Multiple bugs may cause a program crash at the same location whereas one input may trigger multiple bugs. A fuzzer must triage crashes conservatively so that no true bugs are removed but the triaging must also be effective to not overload the analyst with redundant crashes.
Coverage wall
The key advantage of fuzzing compared to more heavyweight analysis techniques is its incredible simplicity (and massive parallelism). Due to this simplicity, fuzzing can get stuck in local minima where continuous input generation will not result in additional crashes or new coverage -- the fuzzer is stuck in front of a coverage wall. A common approach to circumvent the coverage wall is to extract seed values used for comparisons. These seed values are then used during the input generation process. Orthogonally, a developer can comment out hard checks such as CRC32 comparisons or checks for magic values. Removing these non-critical checks from the program requires a knowledgeable developer that custom-tailors fuzzing for each program.
Several recent extensions [SGS+16, RJK+17, PSP18, ISM+18] try to bypass the coverage wall by automatically detecting when the fuzzer gets stuck and then leveraging an auxiliary analysis to either produce new inputs or to modify the program. It is essential that this (sometimes heavyweight) analysis is only executed infrequently as alternating between analysis and fuzzing is costly and reduces fuzzing throughput.
Fuzzing libraries also faces the challenge of experiencing low coverage during unguided fuzzing campaigns. Programs often call exported library functions in sequence, building up complex state in the process. The library functions execute sanity checks and quickly detect illegal or missing state. These checks make library fuzzing challenging as the fuzzer is not aware of the dependencies between library functions. Existing approaches such as LibFuzzer require an analyst to prepare a test program that calls the library functions in a valid sequence to build up the necessary state to fuzz complex functions.
Evaluating fuzzing
In theory, evaluating fuzzing is straight forward: in a given domain, if technique A finds more unique bugs than technique B, then technique A is superior to technique B. In practice, evaluating fuzzing is incredibly hard due to the randomness of the process and domain specialization (e.g., a fuzzer may only work for a certain type of bugs or in a certain environment). Rerunning the same experiment with a different random seed may result in a vastly different number of crashes, discovered bugs, and number of iterations. A recent study [KRC+18] evaluated the common practices of recently published fuzzing techniques (and therefore also serves as overview of the current state of the art, going beyond this article). The study identified common benchmarking crimes when comparing different fuzzers and condensed their findings into four observations:
- Multiple executions: A single execution is not enough due to the randomness in the fuzzing process. Input mutation relies on randomness to decide (according to the mutation strategy) where to mutate input and what to mutate. In a single run, one mechanism could discover more bugs simply because it is “lucky”. To evaluate different mechanisms, we require multiple trials and statistical tests to measure noise.
- Crash triaging: Heuristics cannot be used as the only way to measure performance. For example, collecting crashing inputs or even stack bucketing does not uniquely identify bugs. Ground truth is needed to disambiguate crashing inputs and to correctly count the number of discovered bugs. A benchmark suite with ground truth will help.
- Seed justification: The choice of seed must be documented as different starting seeds provide vastly different starting configurations and not all techniques cope with different seed characteristics equally well. Some mechanisms require a head start with seeds to execute reasonable functionality while others are perfectly fine to start with empty inputs.
- Reasonable execution time: Fuzzing campaigns are generally executed for multiple days to weeks. Comparing different mechanisms based on a few hours of execution time is not enough. A realistic evaluation therefore must run fuzzing campaigns at least for 24 hours.
These recommendations make fuzzing evaluation more complex. Evaluating each mechanism now takes considerable amount of time with experiments running multiple days to get enough statistical data for a fair and valid comparison. Unfortunately, such a thorough evaluation is required as it enables a true comparison and a discussion of factors that enable better fuzzing results.
A call for future work
With the advent of coverage-guided greybox fuzzing [Zal13, Swi10], dynamic testing has seen a renaissance with many new techniques that improve security testing. While incomplete, the advantage of fuzzing is that each reported bug comes with a witness that allows the deterministic reproduction of the bug. Sanitization, the process of instrumenting code with additional software guards, helps to discover bugs closer to their source. Overall, security testing remains challenging, especially for libraries or complex code such as kernels or large software systems. As fuzzers become more domain specific, an interesting challenge will be the comparison across different domains (e.g., comparing a grey-box kernel fuzzer for use-after-free vulnerabilities with a blackbox protocol fuzzer is hard). Given the massive recent improvements of fuzzing, there will be exciting new results in the future. Fuzzing will help make our systems more secure by finding bugs during the development of code before they can cause any harm during deployment.
Fuzzing currently is an extremely hot research area in software security with several new techniques being presented at each top tier security conference. The research directions can be grouped into improving input generation, reducing the performance impact for each execution, better detection of security violations, or pushing fuzzing to new domains such as kernel fuzzing or hardware fuzzing. All these areas are exciting new dimensions and it will be interesting to see how fuzzing can be improved further.
References
[Zal13] Michał Zalewski. American Fuzzy Lop (AFL). http://lcamtuf.coredump.cx/afl/technical_details.txt 2013.
[Swi10] Robert Swiecki. Honggfuzz. https://github.com/google/honggfuzz/ 2010.
[SBP+12] Konstantin Serebryany and Derek Bruening and Alexander Potapenko and Dmitry Vyukov. AddressSanitizer: A Fast Address Sanity Checker. In Usenix ATC 2012.
[JBC+17] Yuseok Jeon and Priyam Biswas and Scott A. Carr and Byoungyoung Lee and Mathias Payer. HexType: Efficient Detection of Type Confusion Errors for C++. In ACM CCS 2017.
[SGS+16] Nick Stephens and John Grosen and Christopher Salls and Andrew Dutcher and Ruoyu Wang and Jacopo Corbetta and Yan Shoshitaishvili and Christopher Krugel and Giovanni Vigna. Driller: Augmenting Fuzzing Through Selective Symbolic Execution. In ISOC NDSS 2016.
[RJK+17] Sanjay Raway and Vivek Jain and Ashish Kumar and Lucian Cojocar and Cristiano Giuffrida and Herbert Bos. VUzzer: Application-aware evolutionary fuzzing. In ISOC NDSS 2017.
[PSP18] Hui Peng and Yan Shoshitaishvili and Mathias Payer. T-Fuzz: fuzzing by program transformation. In IEEE Security and Privacy 2018.
[ISM+18] Insu Yun and Sangho Lee and Meng Xu and Yeongjin Jang and Taesoo Kim. QSYM: A Practical Concolic Execution Engine Tailored for Hybrid Fuzzing. In Usenix SEC 2018.
[KRC+18] George Klees and Andrew Ruef and Benji Cooper and Shiyi Wei and Michael Hicks. Evaluating Fuzz Testing. In ACM CCS 2018.