Just like every year, this year's NDSS was mid February in sunny (but not too warm) San Diego. To help cure the minimal 3 hour jetlag, I enjoyed a couple of morning runs with some of my colleagues -- if you want to get a workout done at a security conference, just let me know and join us! The paper selection this year was great, just as usual. The keynote talks were amazing, more on this later as well. During the opening notes, Alina Oprea and Patrick Treynor commented on how to improve the reviewing process. One thing that changed this year was that we had a set of workshops on the day before the conference.
The workshops were vastly extended compared to prior years. Yours truly and Matthew Smith served as workshop chairs. Compared to the last years we broadly searched for new workshops and poached different people to submit new and exciting workshop proposals. In the end we received seven great workshop submissions out of which we were able to accept four due to space constraints. The workshop I was most looking forward too was the BAR (Workshop on Binary Analysis Research) as it highly overlapped my research interests.

The Workshop on Binary Analysis Research (BAR)
Due to a flight delay I missed the first half of the workshop day and only sneaked in shortly before lunch. The keynote, as I heard, was amazing. Brendan Dolan-Gavitt discussed Prospects and Pitfalls for a Science of Binary Analysis. Binary analysis is in a renaissance. Since the DARPA Cyber Grand Challenge a lot of new research in binary analysis has sprung up, greatly increasing the precision and scaling approaches to larger and more realistic binaries.
Brendan lamented the absence of versatile datasets. In other areas, such as image recognition, representative datasets have helped push towards ever increasing progress. Effective datasets must be curated and tailored to a problem. Interestingly, in system security research we often primarily use a set of standard benchmarks to measure CPU and compiler performance (SPEC CPU2006). This set of benchmarks has nothing to do with security. We need datasets to test bug finding tools but also malware analysis tools.
For bug finding, the DARPA CGC and LAVA datasets have changed the status quo somehow and tools are finding more and more vulnerabilities in those benchmarks. Both of these benchmarks are somewhat artificial, either with injected bugs or with bugs that programmers purposefully placed. The best bug finding tools now already find a large percentage of the synthetic bugs, so we'll soon have to develop new datasets. Datasets for malware analysis have the problem that there is no ground truth. It is somewhat dubious if a dataset is representative as malware campaigns quickly change to react to new malware detection mechanisms.
Binary analysis tasks may be hard and we don't know yet how helpful machine learning will be as the datasets are hard to understand. As a common pitfall, Brendan mentioned that coreutils binaries share up to 94% of code. Machine learning approaches therefore will have a hard time to split the programs into train and test datasets, resulting in over-fitting. The evaluation will test based on the training set, skewing results.
The point Brendan tries to make here is that it's hard to assess a datasets validity. I.e., given a dataset is it representative of the status quo, the hard problems, and the current trends? Large, well-labeled public datasets are crucial to progress in binary analysis. While we have made some progress in the past, the road ahead is long and we will need to constantly improve our datasets. As a community we can together work on this problem.
In the afternoon, the Evolving Exact Decompilation talk by Matt from GrammaTech was very impressive. The idea is simple yet super effective: leverage a genetic optimization algorithm to infer source code from a binary. Start with a simple skeleton, extract strings and constants from the binary, then drive a genetic algorithm to compile the binary to byte equivalent code. The optimization function is simply the edit distance to the source binary. This approach worked surprisingly well for smallish binaries. I do recommend reading the paper.
The paper sessions were followed by a real round table -- great job at moving all those desks and chairs around! The round table focused on the present and near future of binary analysis tooling. We discussed topics such as developments of inter-changeable data formats. Using a common IR seemed to be out of the question, mostly as many groups have already invested a lot of effort into developing their own IRs, highly optimized for their use cases. But developing a data interchange format similar to the CNF format used in SAT solvers may be feasible. CNF is at this interesting intersection where the format far from the internal representation that solvers use but transformable to all formats without loss of generalization. Other topics were datasets, remarks based on Brendan's keynote, open-sourcing, and reproducibility of results. Yan and Fish, the workshop chairs, promised to write a longer blog post about the round table and I'm looking forward to that!
Beyond Smarts: Toward Correct, Private, Data-Rich Smart Contracts
Ari Juels gave an inspiring keynote on blockchains and smart contracts. His idea was to implement a verifiable bug bounty program on top of Hydra, their system of a dynamic correct private smart contract system that combines the advantages of SGX and smart contracts. Hydra combines smart contracts in the block chain with SGX, SGX provides fast computation, integrity but no availability while smart contracts provide the necessary availability. As an outside I found the idea compelling as it would simplify the computation required in a contract somewhat. We had long discussions during the coffee break about the keynote, which is exactly what a keynote should inspire you to.
The Long Winding Road from Idea to Impact in Web Security
Parisa Tabriz, the self-proclaimed browser boss and security princess talked about challenges in securing large browsers. After the dust of the publication settles, there's still a long road to getting a proposed defense or mitigation into a mainline browser. This road involves a lot of engineering, policy changes, and discussions at all levels of abstraction. Having a research idea and simply showing an implementation prototype is not enough! The talk focused on three major thrusts to improve browser security: retiring Adobe Flash, https as default, and per-iframe isolation.
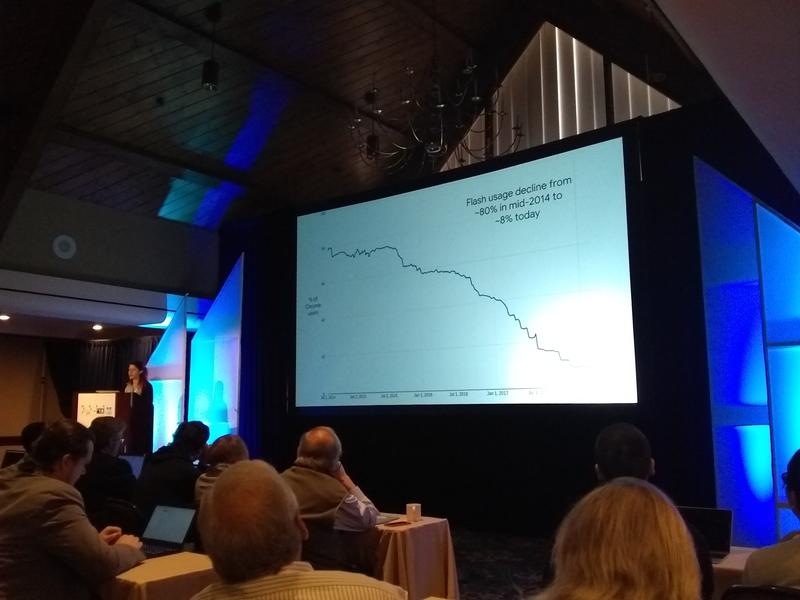
Flash was at fault for the majority of exploitable bugs in Google Chrome. Since 2005 there were more than 1,000 vulnerabilities with assigned CVE numbers. This is a low bar of all bugs as not all bugs get a CVE. Simply removing flash was not an option as people expect the web to just work, a browser must render legacy and broken content. The long road to remove flash consisted of a thousand little changes. First, they bundled Flash to increase user convenience which enabled Google to push auto updates. Second, they added mitigations to quickly disable plugins and whitelist plugin usage on a per-domain basis. Third, they started fuzzing flash based on a large corpus (being a search company kind of helps finding a large set of flash files). The fuzzing on 2,000 cores resulted in 400 unique crashes and 106 0-days. Fourth, they introduced bug bounties for Flash bugs. Fifth, they sandboxed flash through PPAPI. Sixth, they started pushing HTML. Seventh, they moved YouTube to HTML5. Eight, Flash now requires click-to-play. Ninth, HTML5 becomes the new default. Tenth, Flash End-Of-Life is set to 2020. Lessons learned: (i) Flash was Google's problem too, despite being made by another company; (ii) dumb fuzzing works great; (iii) incident response instigated better architecture; (iv) an ecosystem change takes time.
HTTPS should be the default and HTTP should be marked as not secure. The initial symbols for the connection status were good (https, valid certificate), dubious, and bad depending on the error status. The new set of symbols simply uses a green lock for a protected connection and a red open lock to signal any error. This branch of work is based on research by Adrienne Porter Felt. Challenges to push for the adoption of those changes were based on (i) motivation (why should we move to HTTPS if HTTP works just fine); (ii) revenue and performance risks as HTTPS may increase the CPU time; and (iii) third party dependencies as some JavaScript libraries did not support https transports. An interesting orthogonal problem were cultural quirks: in Japan, small companies started to adopt HTTPS based on shame only after a big mover could be convinced (i.e., it was embarrassing not to have HTTPS after the big player adopted HTTPS). Lessons learned: (i) Google needed a business case for change; (ii) research was critical to make changes; (iii) ecosystem change takes time; (iv) conspiracy theories are abound!
Individual iframes should be isolated from each other. Let's use Chrome's sandbox to isolate them! This challenge ultimately turned into a refactoring project for Google Chrome. The renderer enforces same-origin policy, if the renderer is compromised then the same-origin policy can be broken. Originally Chrome used WebKit as renderer but the continuing changes were too drastic, so Chrome forked WebKit into Blink in 2013. The overall goal is to run the evil.com iframe in a different renderer process than the good.com website (which loads evil.com). As a side note, Spectre/Meltdown can read anything from its address space. Per-site process is perfect mitigation for such issues. Google Chrome is moving to full per-site isolation to protect individual frames. Lessons learned: (i) redesigning an engine in flight takes longer; (ii) details really matter; (iii) research can be prioritized; (iv) defense in depth pays off.
Overall, this was the best keynote I've seen in a long time and I thoroughly enjoyed the deep discussions and details Parisa provided. If you have spare time, check out the Chromium Security page and I hope that the recording of the keynote will become available!
Paper Highlights
The NDSS conference was obviously not just about keynotes but also had great research paper sessions. I was a little too slow to be session chair as, when I replied to the email asking for chairs, all the sessions in my area were already covered.
The first session contained a great set of IoT fuzzing papers. In IoTFuzzer: Discovering Memory Corruptions in IoT Through App-based Fuzzing, Jiongyi Chen, Wenrui Diao, Qingchuan Zhao, Chaoshun Zuo, Zhiqiang Lin, XiaoFeng Wang, Wing Cheong Lau, Menghan Sun, Ronghai Yang, and Kehuan Zhang extract data from Android controller applications to generate a fuzzing corpus. Later in What You Corrupt Is Not What You Crash: Challenges in Fuzzing Embedded Devices, Marius Muench, Jan Stijohann, Frank Kargl, Aurelien Francillon, and Davide Balzarotti leverage different signals to test what the underlying reason for a bug is, e.g., TCP connection reset to infer internal state of the embedded device when fuzzing it.
The session software attacks and secure architectures contained with another set of interesting papers. In KeyDrown: Eliminating Software-Based Keystroke Timing Side-Channel Attacks Michael Schwarz, Moritz Lipp, Daniel Gruss, Samuel Weiser, Clémentine Maurice, Raphael Spreitzer, and Stefan Mangard discuss how interrupt timing channels allow inference of key presses. They propose to add random interrupts to mitigate this side channel. In Securing Real-Time Microcontroller Systems through Customized Memory View Switching Chung Hwan Kim, Taegyu Kim, Hongjun Choi, Zhongshu Gu, Byoungyoung Lee, Xiangyu Zhang, and Dongyan Xu encapsulate safe area in microcontroller to protect parts of critical functionality and to detect/mitigate attacks. The encapsulation mechanism has very low performance and memory overhead but requires some manual instrumentation. Later in Tipped Off by Your Memory Allocator: Device-Wide User Activity Sequencing from Android Memory Images by Rohit Bhatia, Brendan Saltaformaggio, Seung Jei Yang, Aisha Ali-Gombe, Xiangyu Zhang, Dongyan Xu, and Golden G. Richard III leverage Android memory images to recover allocation sequences and application details.
Out of obvious reasons, the software security session was the most interesting one -- this was the session for our HexHive paper and my favorite other paper. First, K-Miner: Uncovering Memory Corruption in Linux by David Gens, Simon Schmitt, Lucas Davi, and Ahmad-Reza Sadeghi propose an extensible full-kernel static analysis system and evaluate it by searching the kernel for memory safety violation. The impressing fact is that the LLVM-based framework scales to the full Linux kernel. Second, CFIXX: Object Type Integrity for C++ by Nathan Burow, Derrick McKee, Scott A. Carr, and Mathias Payer introduces Object Type Integrity, a new security policy that protects vtable pointers for C++ applications against adversary-controlled writes. C++ objects may only be created by legit program flow through a constructor call. Virtual dispatch is adjusted to leverage the protected vtable pointers, thereby guarding control flow. You should obviously read both paper and start with the CFIXX paper!

The paper Superset Disassembly: Statically Rewriting x86 Binaries Without Heuristics by Erik Baumann, Zhiqiang Lin, and Kevin Hamlen proposes a static reassembler that leverages the concepts of dynamic binary translation. The retranslator builds on a set of of assumptions and ideas: First, keep data static and constant, assume that references to data remain fine. Second, create mapping from old addresses to new addresses (similar to dynamic BTs). Third, rewrite all executable data to differentiate code from data. Fourth, rewrite all libraries to cover all executable code. The performance and memory overhead is still a little on the high side but the idea is interesting
An honorable mention goes to the two interesting web security talks JavaScript Zero: Real JavaScript and Zero Side-Channel Attacks and Riding out DOMsday: Towards Detecting and Preventing DOM Cross-Site Scripting.