As part of ESSoS ‘17 we have organized a joint ESSoS/DIMVA panel on exploit mitigations, discussing the past, present, and future of mitigations. If we look at the statistics of reported memory corruptions we see an upward trend in number of reported vulnerabilities. Given the success of contests such as pwn2own one might conclude that mitigations have not been effective while in fact, exploitation has become much harder and costly through the development of mitigations.

Over the last 15 years we as a community have developed a set of defenses that make successful exploitation much harder, see our Eternal War in Memory paper for a systematization of all these mitigations. With stack cookies, software is protected against continuous buffer overflows, which stops simple stack smashing attacks. About 10 years go, the combination of Address Space Layout Randomization -- ASLR, which shuffles the address space -- and Data Execution Prevention -- DEP, which enforces a separation between code and data -- increased the protection against code reuse attacks. DEP itself protects against code injection but requires ASLR to protect against code reuse attacks. In the last 2 years, Control-Flow Integrity -- CFI, a policy that restricts the runtime control flow to programmer intended targets -- has been deployed in two flavors: coarse-grained through Microsoft’s Control-Flow Guard and fine-grained through Google’s LLVM-CFI. In addition, Intel has proposed a fine-grained shadow stack to protect the backward edge (function returns) and a coarse-grained forward-edge mechanism to protect indirect function calls that will be implemented in hardware. See an earlier blogpost or our survey for a discussion of the different CFI mechanisms.
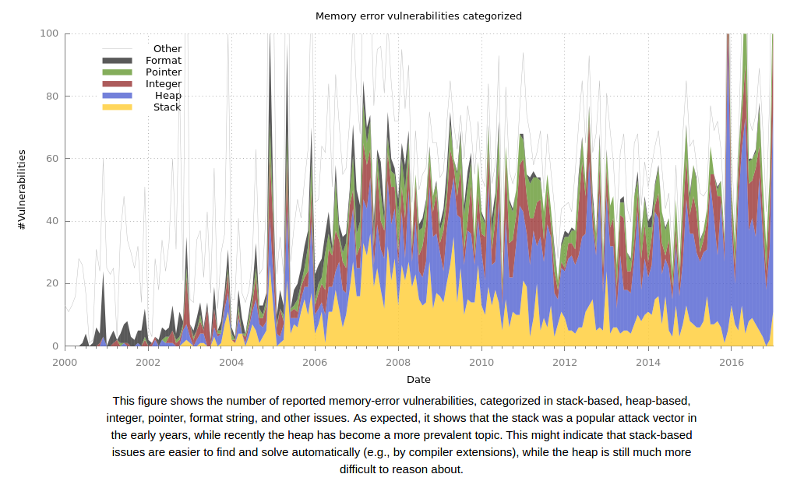 Memory corruption vulnerabilities over time. Thanks to Victor van der Veen from
VU for the data.
Memory corruption vulnerabilities over time. Thanks to Victor van der Veen from
VU for the data.
We started off the panel with brief mission statements and an introduction of the three panelists: Thomas Dullien, Cristiano Giuffrida, and Michalis Polychronakis. Yours truly served as the humble (and only slightly biased) moderator.
Thomas Dullien from Google started the introduction round. Coming from an academic background but having switched to industry after doing a malware and reverse engineering startup has exposed him to a lot of security practice. He argued that none of the academic proposals (except for CFI) are deployed (ASLR + DEP originated outside academia, although one could argue that stack cookies started in academia and were refined to practicality in industry) and that academia has been optimizing for the wrong metrics. Academics often follow a partial view of attacks and do not consider the full system stack. In addition, attacks may only be partially stopped or a defense protects against a primitive instead of against an attack vector. In his opinion, academics should think about what they want to mitigate and clearly define their attacker models and threat models. Thomas argued for compartmentalization, moving untrusted components into sandboxes and protecting the remaining code with strong mitigations.
Cristiano Giuffrida from VUsec at VU Amsterdam mentioned their research in different mitigations and stressed that they focus on practical defenses. VUsec is known for CFI mitigations for binaries and source code and for novel approaches that target type safety. Focusing on systems research, VUsec is building frameworks for mitigations such as a generic metadata storage system. Going beyond defenses, VUsec is also known for different attacks leveraging combinations of rowhammer to flip bits (i.e., using it as a write primitive) with different side channels (i.e., using it as read primitive) to allow exploitation beyond any attacker model used in current mitigations. Cristiano argued for metrics along multiple dimensions. To effectively compare different mitigations, we need to develop clear metrics along performance (CPU) cost, memory cost, binary compatibility, and functional compatibility.
Michalis Polychronakis from Stony Brook talked about their research on probabilistic defenses. Protecting different domains poses new and interesting challenges. For example, protecting operating system kernels requires knowledge of the underlying data structures and the degrees of freedom are limited as both user-space and kernel-space are designed with certain assumptions. Another point Michalis brought up is compatibility and the need to protect binary-only programs. Binaries are always available and development of binary analysis techniques allows protection of any code. Source code may be more precise initially but deployment will be harder, especially when some components are not available as open-source such as the libc or proprietary libraries. Michalis agreed that compatibility is challenging and that useful defenses will be low (zero) overhead, highly compatible, and mitigate complete attack classes.
After the initial position statements we iterated over several main discussion topics: CFI and it’s research success, sandboxing, composition of mitigations, hardware deployment, reproducibility, metrics, and benchmarks.
The first discussion topic was transfer of academic research to practice at the example of CFI. CFI has been proposed by academics and academia has worked tirelessly for the last 10 years to refine CFI policies. CFI has been adapted to kernel and user-space, for binaries and source code, and all at different levels of granularity and precision. Generally, the performance and memory overhead is low to negligible. In addition to many software implementations, CFI is on the verge of being deployed in hardware through Intel’s CET extensions. The panelists agreed that CFI makes exploitation harder but quantifying this additional hardness is hard and program dependent. CFI is especially not useful in all contexts and academics should not apply CFI everywhere. For example, in browsers a JIT compiler/interpreter allows the attacker to generate new code based on attacker-controlled data. As the JIT compiler, the generated code, and all other code and data are co-located in a single process, simply protecting the existing code is not enough to stop an attacker. Another example are operating system kernels. An attacker achieves her goals by simply flipping bits in important data structures such as the user id in the process struct or pointers in the page table. Even if the control-flow is protected through CFI, data-only attacks are much more severe and direct. Orthogonally, sandboxing individual components and enforcing least privilege will be more effective than simply restricting control flow. All's not lost though, CFI is useful in particular locations and makes code reuse attacks harder. The question academics (and the community) should answer is how much harder an attack becomes.
An orthogonal vector is hardware deployment of mitigations. Intel is targeting a hardware deployment of a strong backward edge but weak forward edge CFI solution. With open source hardware such as RISC-V defense mechanisms with hardware support can realistically be tested by researchers, leveling the playing field between academia and industry.
Sandboxing/least privilege is a simple and well known mitigation technique that restricts a module to a well-defined API, limiting interactions with other code. Compartmentalization (and sandboxing) is likely more effective than many other mitigations proposed by academia. What makes sandboxing hard is the requirement for a redesign of the software. For example, the two main mail servers qmail and sendmail are fundamentally different. While sendmail follows a monolithic design qmail is split into many different components with minimal privileges. To enable clear separation, qmail had to be designed from scratch to enforce this level of separation with minimal privileges for individual components. An interesting question is how to move from monolithic software to individually sandboxed components.
As one mitigation alone is clearly not effective against all possible attack vectors, it becomes clear that a combination of mitigations is required to defend a system. Mitigations may interact at multiple levels and composition of defenses is an unsolved problem. One mitigation may protect against one attack vector but make another attack vector easier. For example randomizing allocators may shuffle different allocation classes. One one hand, this makes overflows into an object of the same class harder but allows overflows into other classes. The interaction between different mitigations may be intricate and we currently do not reason about these interactions. It would be interesting to develop a model that allows such a reasoning.
Benchmark suites, or the lack thereof, is another problematic topic when evaluating mitigations. Many publications are prone to benchmarking crimes. Defenses are evaluated using only a subset of standard benchmarks (e.g., SPEC CPU2006 for performance) where individual benchmarks are cherry picked. Binary-only defenses are often only run with simple binaries such as the binutils or other simple small binaries, often excluding the libc. In general, defenses must be evaluated using the full benchmark suite to enable comparison between different techniques in addition to realistic work loads. For example, for compiler-based defenses at least browsers such as Firefox or Chrome should be evaluated and for binary analysis mechanisms at least Adobe Acrobat Reader and a libc must be evaluated to show that the techniques can cope with the complexity of real systems. Going forward we have to develop benchmarks that evaluate security properties as well, likely for individual attack vectors (Lava is an example of such a framework). This would allow a centralized testing infrastructure for different mechanisms and a quantitative comparison of mechanisms compared to the qualitative arguments that are currently used.
Reproducibility is a big problem in academia. Many defenses are simply published in paper form with some performance evaluation. Reproducing the results of a paper is hard and most of the time impossible. Papers that overclaim their solutions without backing up the results through an open-source mechanism cannot be reproduced and should be considered with a grain of salt. Going forward, we should push the community towards releasing implementation prototypes but under the assumption that these are implementation prototypes and not production mechanisms. One solution could be to release docker containers with the specific software that allows reproducing the results. If required, the software license could be restricted to only allow reproduction of results. This is a fine line, one one hand we want to compare against other mechanisms but on the other hand bugs that are orthogonal to the defense policy should not become a reason to attack an open-sourced defense.
Generally, it is hard to evaluate defense mechanisms resulting in a multi dimensional problem -- especially for system security. System security inherits the evaluation criteria from systems. Systems research requires rigorous evaluation of a prototype implementation along the dimensions of runtime performance and memory overhead. Sometimes complexity of the proposed system is evaluated as well. As defenses are complementary to a system (i.e., they build on top of a system) the additional complexity becomes much more problematic. In addition, we have to come up with metrics to evaluate different threat models and attacks, allowing us to infer how much harder an attack becomes given that a specific defense is used.
Current computers and their systems are hugely complex and only deterministic in abstraction. Many concurrent layers interact with often hard to distinguish effects. Security crosscuts all the layers of our systems from hardware to the highest layer of the software stack. Defenses have to reason along all these layers and the guarantees may be broken at any layer. While we often argue from the top of the stack down (or from a theoretical aspect), we should approach an electrical engineering view down to the lowest level.
When transitioning defenses into practice, researchers are often faced with additional difficulties. Defenses add overhead along several dimensions and increase the complexity of a software system. Researchers therefore need to argue in favor of their system. Attacks on the other hand are purely technical as an exploit proofs that a defense can be bypassed. In short: offense is technical while defense is political. Even shorter: you cannot argue against a root shell.